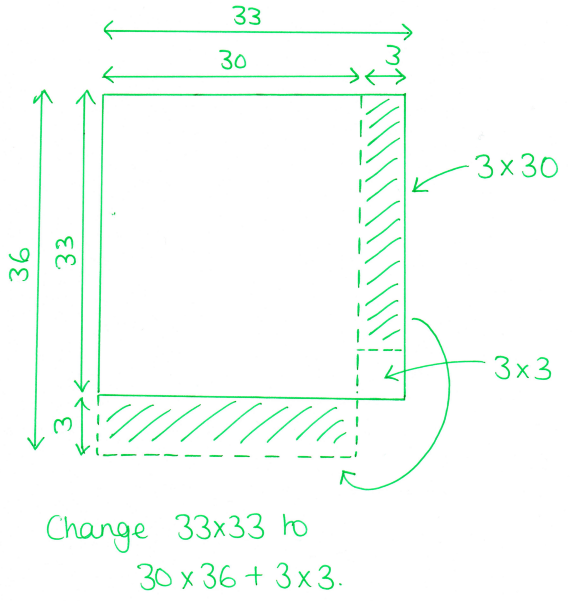
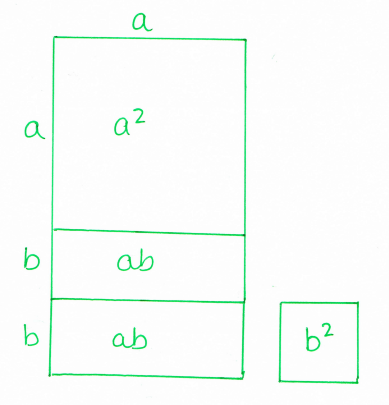
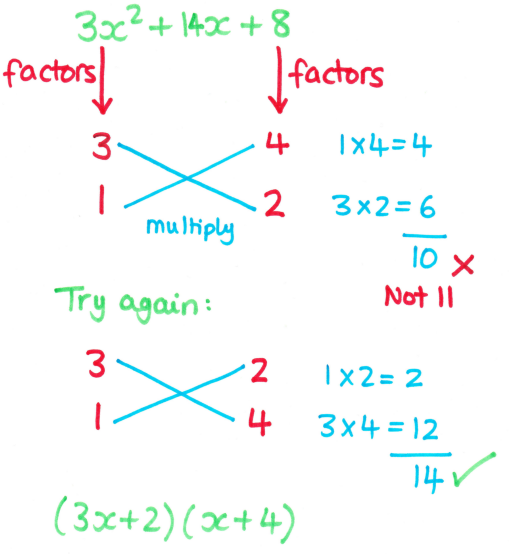
Working forwards...
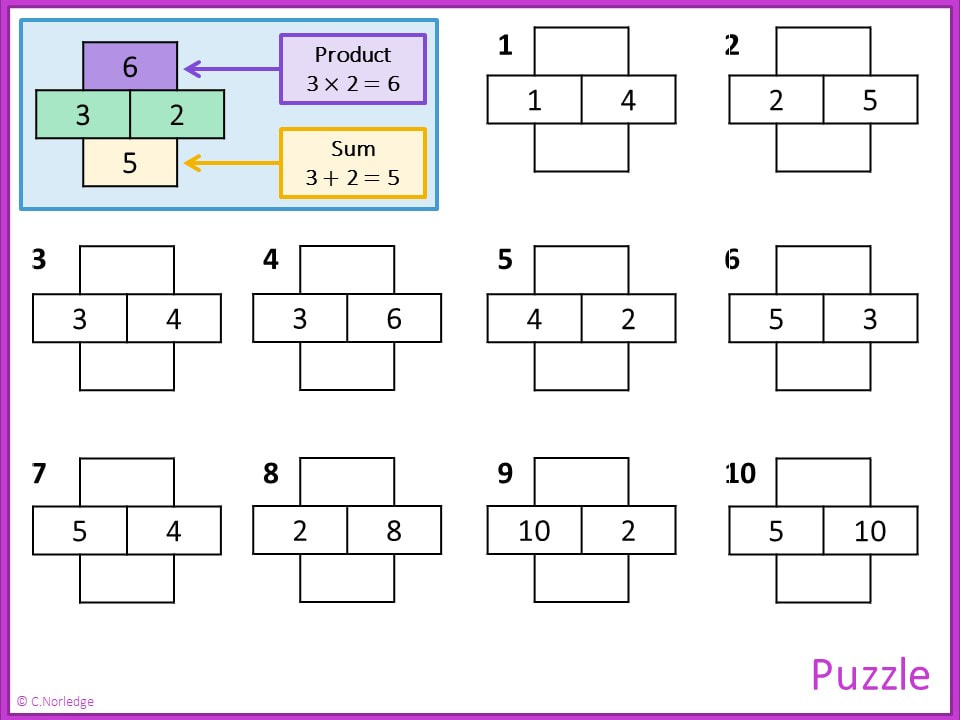
These puzzles are useful as a starter or quick introductory activity for expanding standard quadratic expressions.
These puzzles are useful as a starter or quick introductory activity for expanding standard quadratic expressions.
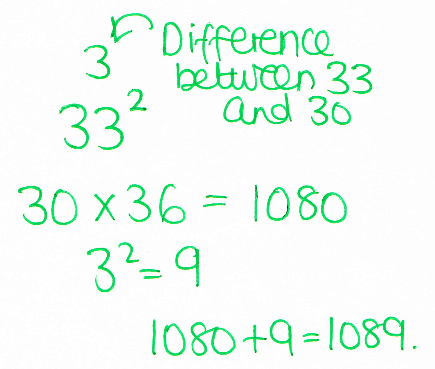
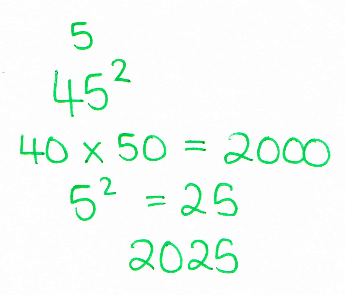
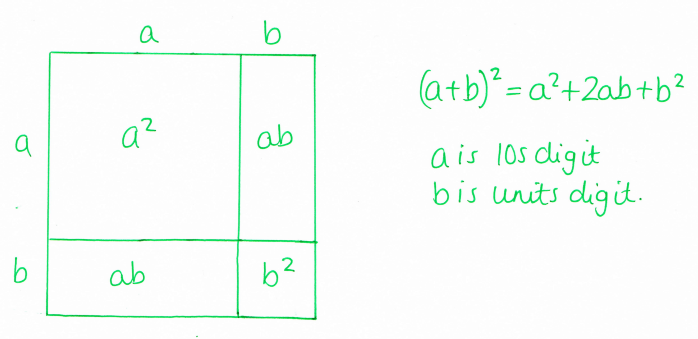
 RSS Feed
RSS Feed
